Measuring the Popularity of Novels?
Apparently, the amount of ratings on GoodReads.com is highly correlated with the ratings, at least for John Green’s four novels (r = .96). But is it really ‘the more, the merrier’? I picked four more authors (in a non-random fashion), had a look at the respective correlations for their novels, and made a couple of graphs to illustrate the results.
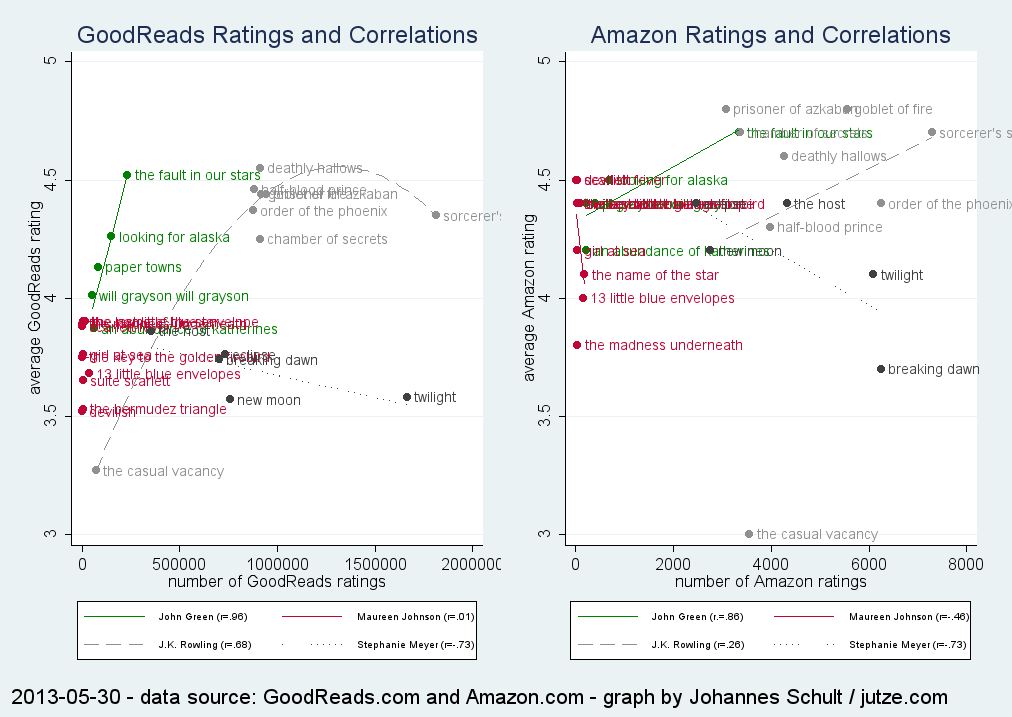
Novels by John Green, Maureen Johnson, J.K. Rowling, and Stephanie Meyer
The relationship is a negative one for Stephanie Meyer’s books. Two books of J.K. Rowling are outliers – her first one in terms of ratings on GoodReads, her most recent one in terms of rating. I therefore took the liberty to plot a quadratic fit (instead of a linear fit). It appears that John Green might be an exception (like the Mongols?) Also, Amazon.com ratings tend to be higher; and again, there is no clear relationship between the amount of reviews and the average rating.
And since I recently finished reading “On Chesil Beach”, here’s the data for Ian McEwan’s novels, along with a more appropriately scaled plot for Maureen Johnson’s books:
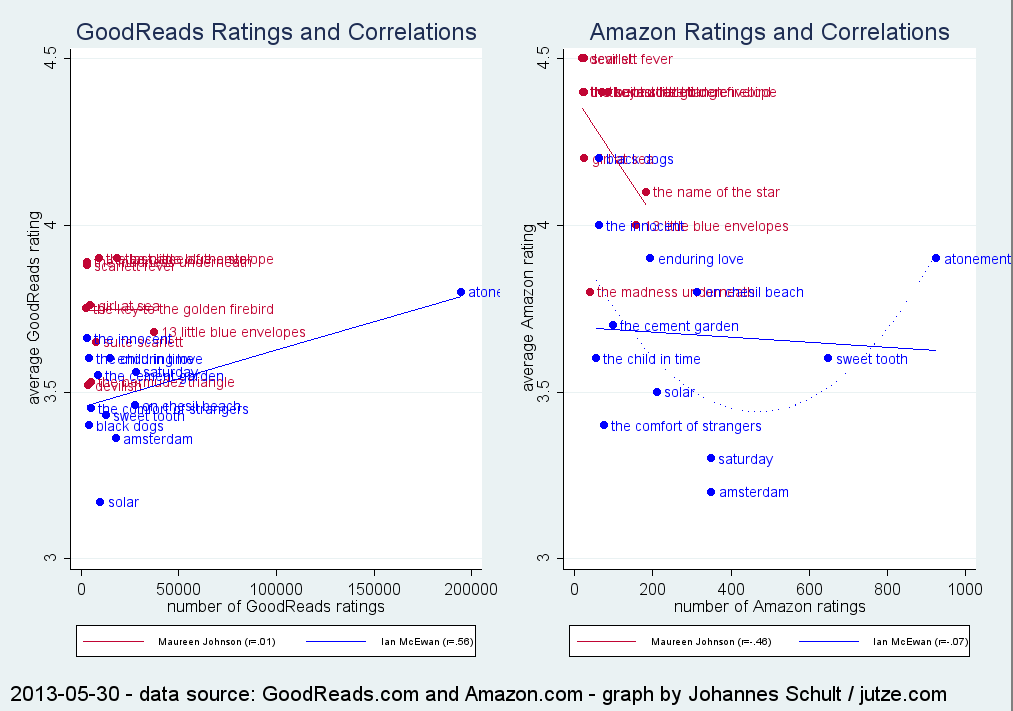
Novels by Maureen Johnson and Ian McEwan
By the way, the correlation between Amazon.com ratings and GoodReads.com ratings for the 40 books I used above is r = .89. The correlation between number of Amazon.com reviews and Goodreads.com ratings is r = .75.
PS: If anyone is interested in the Stata code for the graphs, let me know. I guess, I’ll add it here this weekend, anyway, but right now I should go to bed.