Metaanalyse zur prädiktiven Validität von Studierfähigkeitstests
Diese Woche erschien “Leisten fachspezifische Studierfähigkeitstests im deutschsprachigen Raum eine valide Studienerfolgsprognose? Ein metaanalytisches Update” (Post-Print bei ResearchGate). Als Erstautor bin ich darüber natürlich in erster Linie erfreut. Die Arbeit ist praktisch die Fortschreibung (bis 2018), Bestätigung (der prädiktiven Validität) und Erweiterung (mehr Fachrichtungen, inkrementelle Validität bzgl. Abinoten) der Metaanalyse von Hell, Trapmann und Schuler (2007). Ich möchte an dieser Stelle kurz ein paar zusätzliche Gedanken festhalten, die insbesondere die Entscheidungen betrifft, die man beim Schreiben eines Artikels unweigerlich treffen muss.
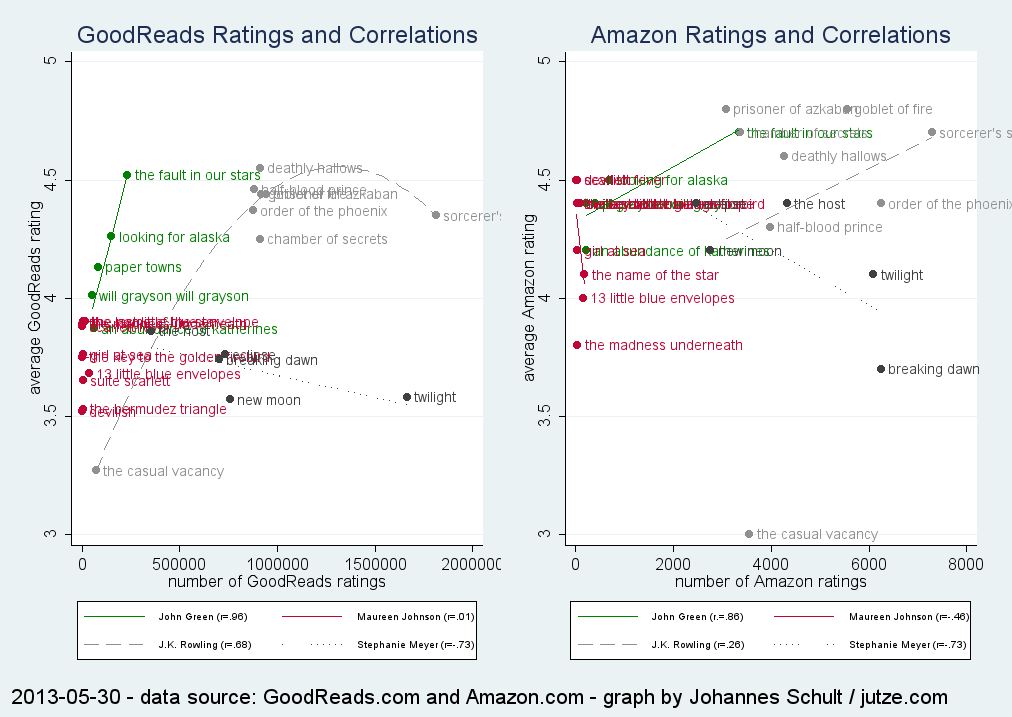
Die neue Metaanalyse orientiert sich stark an der alten, ist aber keine sklavische Wiederholung. So wurde anno 2019 als Software R verwendet. Das ist bei Validitätsmetaanalysen nicht unbedingt geradlinig. Ursprünglich hatte ich vor, das Paket psychmeta zu verwenden. Für die anschließenden Moderatoranalysen sowie für den Fokus auf Fixed-Effects-Modelle war am Ende aber metafor das Paket der Wahl, das die Analyse “im Stil” der Methode von Hunter und Schmidt vornimmt.
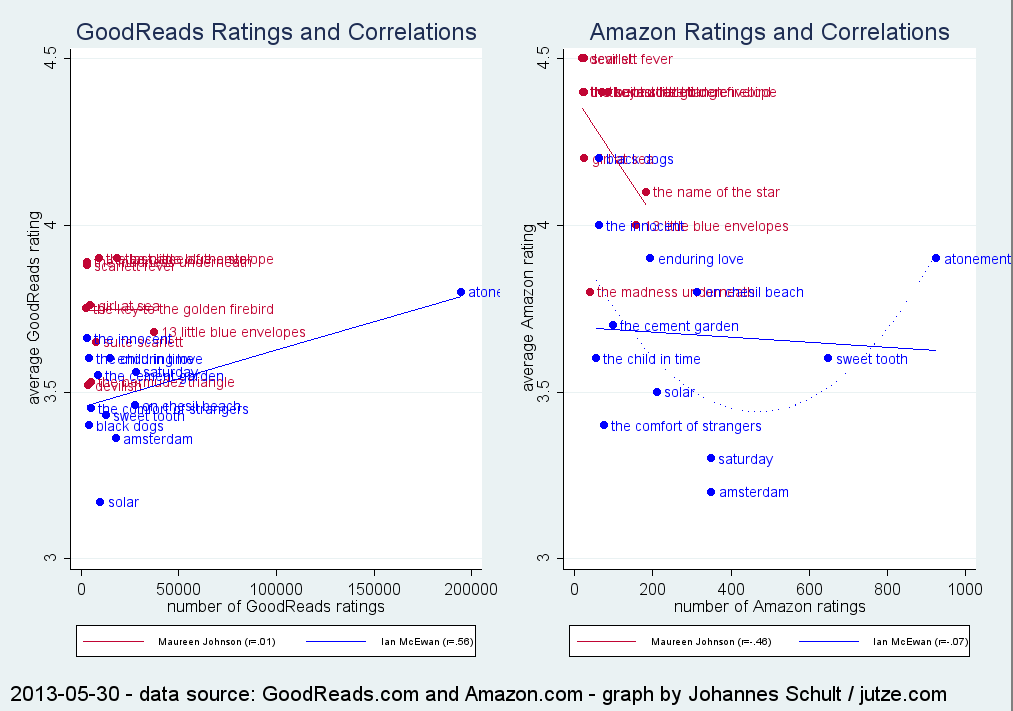
Es gab die Überlegung, die Studien der Hell-Metaanalyse auch in die Analyse mit einzubeziehen. Dann wäre die neue Arbeit aber nicht so eigenständig ausgefallen. Vielleicht nimmt sich in Zukunft ja jemand der Aufgabe an, alle Studien (seit 1980?) zusammenzufassen. Wir haben nicht zuletzt dafür die Datenmatrix unserer Analysen online gestellt, um möglichst transparent und replikabel (?) zu sein.
Die Betrachtung der inkrementellen Validität von Studierfähigkeitstests über die Abinote hinaus war mir wichtig, weil das Thema in der Praxis sehr präsent ist. Die Vermutung von Hell, Trapmann und Schuler (2008), dass es ein Inkrement im hohen einstelligen Prozentpunktbereich gibt, konnte numerisch bestätigt werden. An der Herausforderung der inferenzstatistischen Prüfung bin ich allerdings gescheitert. Deshalb fällt der Inkrement-Punkt im Artikel eher knapp aus. Ich bin auch skeptisch, dass es eine Spezialform des Wald-Tests gibt, die den Test mit den spärlich vorhandenen Daten rechnen könnte. Vielversprechender wäre eine Metaregression, für die aber in den Primärstudien die vollständigen Korrelationsmatrizen (mit Abinoten, Testleistungen und Studiennoten) berichtet werden müssen – was bislang nur in selten passiert ist. Dies ist also Zukunftsmusik.
Fazit: Ungeachtet dieser Punkte sehe ich die Arbeit positiv und die Ergebnisse als belastbar an. So freue ich mich auch auf die große, positive Resonanz auf unsere Metaanalyse, die es jüngst bei der DPPD-Fachgruppentagung sowie bei der BMBF-Fachtagung zu Eingangstests gab. Mal sehen, wer 2031 die nächste Metaanalyse zum Thema macht!
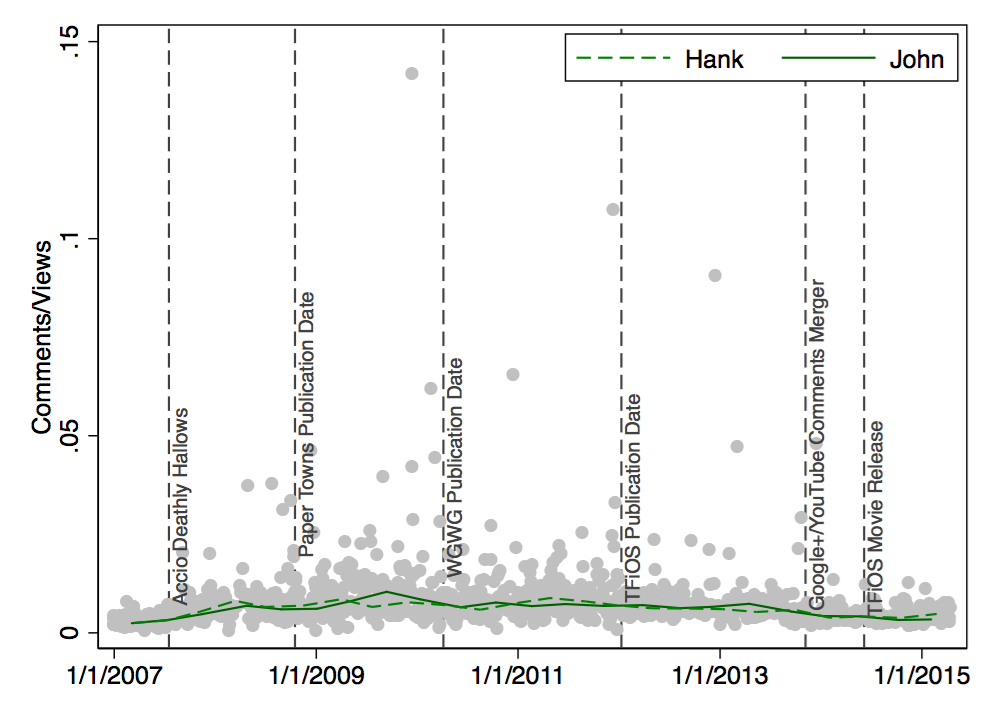

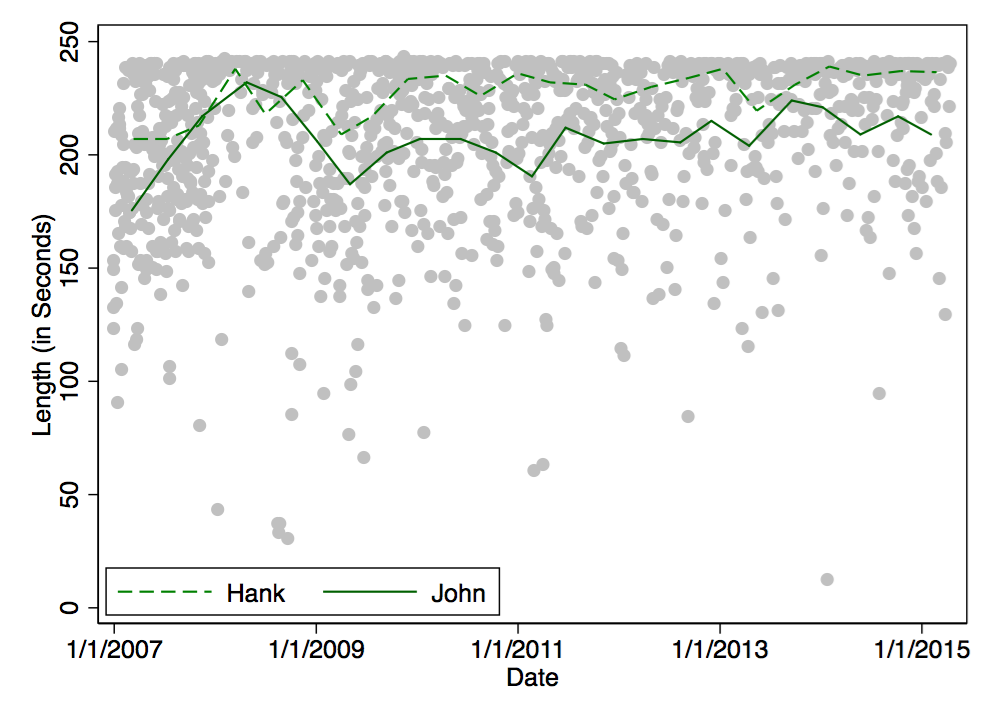
 - click for larger version - see below for full album names")
 - click for larger version - see below for full album names")